Home
News
People
Publications
Recruitment
Light
Dark
Automatic
English
中文 (简体)
Manuscript
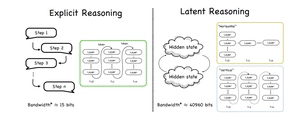
A Survey on Latent Reasoning
Rui-Jie Zhu
,
Tianhao Peng
,
Tianhao Cheng
,
Xingwei Qu
,
Jinfa Huang
,
Dawei Zhu
,
Hao Wang
,
Kaiwen Xue
,
Xuanliang Zhang
,
Yong Shan
,
Tianle Cai
,
Taylor Kergan
,
Assel Kembay
,
Andrew Smith
,
Chenghua Lin
,
Binh Nguyen
,
Yuqi Pan
,
Yuhong Chou
,
Zefan Cai
,
Zhenhe Wu
,
Yongchi Zhao
,
Tianyu Liu
,
Jian Yang
,
Wangchunshu Zhou
,
Chujie Zheng
,
Chongxuan Li
,
Yuyin Zhou
,
Zhoujun Li
,
Zhaoxiang Zhang
,
Jiaheng Liu
,
Ge Zhang
,
Wenhao Huang
,
Jason Eshraghian
PDF
Cite
arXiv
URL
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Zhongyuan Peng
,
Yifan Yao
,
Kaijing Ma
,
Shuyue Guo
,
Yizhe Li
,
Yichi Zhang
,
Chenchen Zhang
,
Yifan Zhang
,
Zhouliang Yu
,
Luming Li
,
Minghao Liu
,
Yihang Xia
,
Jiawei Shen
,
Yuchen Wu
,
Yixin Cao
,
Zhaoxiang Zhang
,
Wenhao Huang
,
Jiaheng Liu
,
Ge Zhang
Cite
arXiv
URL
HiPO: Hybrid Policy Optimization for Dynamic Reasoning in LLMs
Ken Deng
,
Zizheng Zhan
,
Wen Xiang
,
Wenqiang Zhu
,
Weihao Li
,
Jingxuan Xu
,
Tianhao Peng
,
Xinping Lei
,
Kun Wu
,
Yifan Yao
,
Haoyang Huang
,
Huaixi Tang
,
Kepeng Lei
,
Zhiyi Lai
,
Songwei Yu
,
Zongxian Feng
,
Zuchen Gao
,
Weihao Xie
,
Chenchen Zhang
,
Yanan Wu
,
Yuanxing Zhang
,
Lecheng Huang
,
Yuqun Zhang
,
Jie Liu
,
Zhaoxiang Zhang
,
Haotian Zhang
,
Bin Chen
,
Jiaheng Liu
Cite
arXiv
URL
IF-VidCap: Can Video Caption Models Follow Instructions?
Shihao Li
,
Yuanxing Zhang
,
Jiangtao Wu
,
Zhide Lei
,
Yiwen He
,
Runzhe Wen
,
Chenxi Liao
,
Chengkang Jiang
,
An Ping
,
Shuo Gao
,
Suhan Wang
,
Zhaozhou Bian
,
Zijun Zhou
,
Jingyi Xie
,
Jiayi Zhou
,
Jing Wang
,
Yifan Yao
,
Weihao Xie
,
Yingshui Tan
,
Yanghai Wang
,
Qianqian Xie
,
Zhaoxiang Zhang
,
Jiaheng Liu
Cite
arXiv
URL
MT-Video-Bench: A Holistic Video Understanding Benchmark for Evaluating Multimodal LLMs in Multi-Turn Dialogues
Yaning Pan
,
Zekun Wang
,
Qianqian Xie
,
Yongqian Wen
,
Yuanxing Zhang
,
Guohui Zhang
,
Haoxuan Hu
,
Zhiyu Pan
,
Yibing Huang
,
Zhidong Gan
,
Yonghong Lin
,
An Ping
,
Tianhao Peng
,
Jiaheng Liu
Cite
arXiv
URL
OmniVideoBench: Towards Audio-Visual Understanding Evaluation for Omni MLLMs
Caorui Li
,
Yu Chen
,
Yiyan Ji
,
Jin Xu
,
Zhenyu Cui
,
Shihao Li
,
Yuanxing Zhang
,
Jiafu Tang
,
Zhenghao Song
,
Dingling Zhang
,
Ying He
,
Haoxiang Liu
,
Yuxuan Wang
,
Qiufeng Wang
,
Zhenhe Wu
,
Jiehui Luo
,
Zhiyu Pan
,
Weihao Xie
,
Chenchen Zhang
,
Zhaohui Wang
,
Jiayi Tian
,
Yanghai Wang
,
Zhe Cao
,
Minxin Dai
,
Ke Wang
,
Runzhe Wen
,
Yinghao Ma
,
Yaning Pan
,
Sungkyun Chang
,
Termeh Taheri
,
Haiwen Xia
,
Christos Plachouras
,
Emmanouil Benetos
,
Yizhi Li
,
Ge Zhang
,
Jian Yang
,
Tianhao Peng
,
Zili Wang
,
Minghao Liu
,
Junran Peng
,
Zhaoxiang Zhang
,
Jiaheng Liu
Cite
arXiv
URL
VR-Thinker: Boosting Video Reward Models through Thinking-with-Image Reasoning
Qunzhong Wang
,
Jie Liu
,
Jiajun Liang
,
Yilei Jiang
,
Yuanxing Zhang
,
Jinyuan Chen
,
Yaozhi Zheng
,
Xintao Wang
,
Pengfei Wan
,
Xiangyu Yue
,
Jiaheng Liu
Cite
arXiv
URL
Cite
×